« Précédent -
Version 17/28
(diff) -
Suivant » -
Version actuelle
Severine Gedzelman, 28/09/2017 13:56
Transformation vers un corpus parallèle (alignement HM)¶
Le document fourni par Uetani est un fichier word, organisé avec des tableaux à 3 colonnes :- col 1 : nom du segment philologique (et notes diverses, dont certains acronymes sont à élucider pour moi)
- col 2 : version italienne
- col 3 : version française correspondante
- le premier est fourni par le service OXGarage (transformateur en ligne pour la communauté TEI principalement)
- le deuxième a été écrit en python par moi-même dont les détails sont après.
1) ODT vers XML-TEI¶
- Le document de départ : CorpusSANAZIFR_Uetani_2017.odt
- Le document de sortie : CorpusSANAZIFR_Uetani_2017.xml
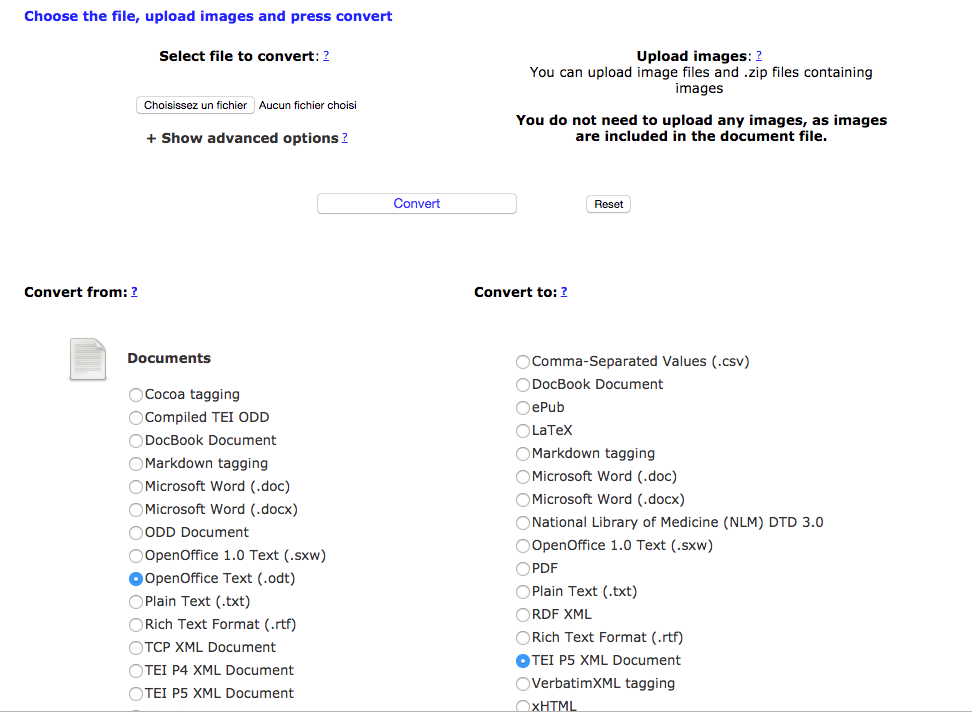
Les choix ont été les suivants sur OxGarage : OpenOffice texte (odt) en entrée, TEI P5 XML Document en sortie
Les tableaux sont restitués avec également les éléments de forme et les notes de bas de page, un exemple de la dernière ligne (<row>) du dernier tableau (<table>) :
<table rend="frame" xml:id="Tableau4">
<row>
<cell>Ecloga II, vv. 1-12</cell>
<cell>....</cell>
<cell>....</cell>
</row>
...
</table>
<table>
...
<row>
<cell>A la Sampogna, 19-20</cell>
<cell rend="justify"><hi rend="bold italic">Benché</hi><hi rend="italic"> mi
pare esser certo che tal fatica a tenon fia necessaria, se tu tra le
selve, sí come io ti impongo, secretamente e senza pompe star ti vorrai.
Con ciò sia cosa che chi non sale, non teme di cadere ; e chi cade nel
piano, il che rare volte adiviene, con picciolo agiuto</hi><hi
rend="italic"><note xml:id="ftn529" place="foot" n="529">
<hi rend="italic">agiuto</hi> : aiuto (E).</note></hi><hi
rend="italic"> de la propria mano senza danno si rileva</hi><hi
rend="italic"><note xml:id="ftn530" place="foot" n="530"><hi
rend="italic"> rileva</hi> : risolleva, rialza
(E).</note></hi><hi rend="italic">. Onde per cosa vera e indubitata
tener ti puoi che chi piú di nascoso e piú lontano da la moltitudine
vive, miglior vive ; e colui tra' mortali si può con piú verità chiamar
beato che, senza invidia de le altrui grandezze, </hi><hi
rend="bold italic">con modesto animo</hi><hi rend="italic"> de la sua
fortuna si contenta (p. 241).</hi></cell>
<cell rend="justify"><hi rend="bold">Nonobstant</hi> je pense estre aßeuré que
n'auras besoing de ce faire, si suyvant mon conseil, tu te veul tenir en ces
boys secretement, & sans aucune pompe : Car qui ne saulte, n'a peur de
tumber : & qui chet en la plaine (ce que n'advient gueres) se relieve
sans dommage, seulement avec un peu de secours de ses propres mains. Parquoy
tu peux tenir pour chose indubitable, que celuy peult vivre en plus grand
repos, qui est plus loingtain & retiré de la multitude confuse. Et entre
les hommes se peult plus veritablement estimer bien heureux celuy qui sans
envie des grandeßes d'aultruy,<hi rend="bold">par </hi><hi
rend="bold italic">modestie</hi><hi rend="bold"> de courage</hi> se
contente de sa fortune (fol. 114 v°).</cell>
</row>
</table>
2) XML-TEI vers XML-TEI-HM¶
Le script tei2teiHM.py permet de- récupérer l'ensemble des deux textes (source italien, cible français) :
- sans les notes (de bas de page)
- sans les indications graphiques (qui sont dans des balises <hi> avec attributs : italic, bold, ...)
- et de préparer la structure et les noms des divisions, et des segments contenus dans celles-ci. Par exemple les segments <seg> "Prosa_X_1", "Prosa_X_2", ... seront rassemblés sous une division <div> : "Prosa_X".
Pour plus d'info, voir le chapitre dédié à la structure philologique, et les opérations de nettoyage effectuées jusqu'à présent.
A propos de la ressource XML en entrée¶
Le document XML-TEI a été légèrement modifié à la main (attachment:)- avec une substitution des "Egloga" en "Ecloga" (peut refaire la modification dans le sens inverse si besoin)
- avec remplacement des valeurs des attributs "xml:id" des tableaux afin de permettre la création de divisions philologiques plus méta comme "Prosa_X", dans lesquels s'inséreront automatiquement les segments philologiques "Prosa_X_1", "Prosa_X_2". L'attribut notait jusqu'à présent seulement l'incrémentation des tableaux : "Tableau1", "Tableau2". Cela donne pour le premier tableau : <table rend="frame" xml:id="Prologo I">
Dans une réflexion semblable, faut-il préparer des <cell> avec les titres des segments, comme par exemple s'est trouvé par hasard le titre de "Ecloga XI". On pourra ainsi les traiter comme des titres en TEI avec la balise <head>.
<table rend="frame" xml:id="Ecloga_XI">
<row>
<cell>Ecloga XI, 0</cell>
<cell rend="center">ERGASTO<hi rend="italic"> solo</hi></cell>
<cell>ERGASTO SEVL.</cell>
</row>
A propos du script et de ses paramètres¶
Le script génère des <teiHeader> pour les deux textes (it, fr) <TEI> et pour l'ensemble du corpus <teiCorpus>. Chaque texte aura un identifiant pour Hypermachiavel avec une langue correspondante :- Erspamer_1505 (i1) - it
- Martin_1544 (f1) - frm
Remarque : Il faudra prévoir d'ajouter ces entêtes manuellement selon les indicatons de Uetani sur ces différentes éditions/productions. J'ai calqué pour l'instant à la structure de Hyperprince, pour les détails, voir le corpus.
Avant d'appeler le script python, il faut- vérifier l'installation de "python" sur la machine (à noter que tous les Mac ont une version par défaut, même chose pour le programme Java)
- placer les ressources dans le même dossier : soit le fichier source de donnée .xml et le fichier script .py,
- indiquer en deuxième paramètre du script, la chaîne correspondant au chemin du dossier où se trouve ces ressources
$ python tei2teiHM.py CorpusSANAZIFR_Uetani_2017.xml ~/Documents/Travail_ENS/Projets/Exterieurs/CESR_Uetani/Transformations
A propos de la ressource générée¶
Le résultat avec le même extrait 'XML-TEI' donné plus haut : A_la_Sampogna_19-20
<seg n="15" type="Segment" rend="A_la_Sampogna_19-20" xml:id="i1_Ch25-Seg15">
Benché mi pare esser certo che tal fatica a tenon fia necessaria, se tu tra le selve, sí
come io ti impongo, secretamente e senza pompe star ti vorrai. Con ciò sia cosa
che chi non sale, non teme di cadere ; e chi cade nel piano, il che rare volte adiviene,
con picciolo agiuto de la propria mano senza danno si rileva. Onde per cosa vera e
indubitata tener ti puoi che chi piú di nascoso e piú lontano da la moltitudine vive,
miglior vive ; e colui tra' mortali si può con piú verità chiamar beato che,
senza invidia de le altrui grandezze, con modesto animo de la sua fortuna si contenta (p. 241).
</seg>
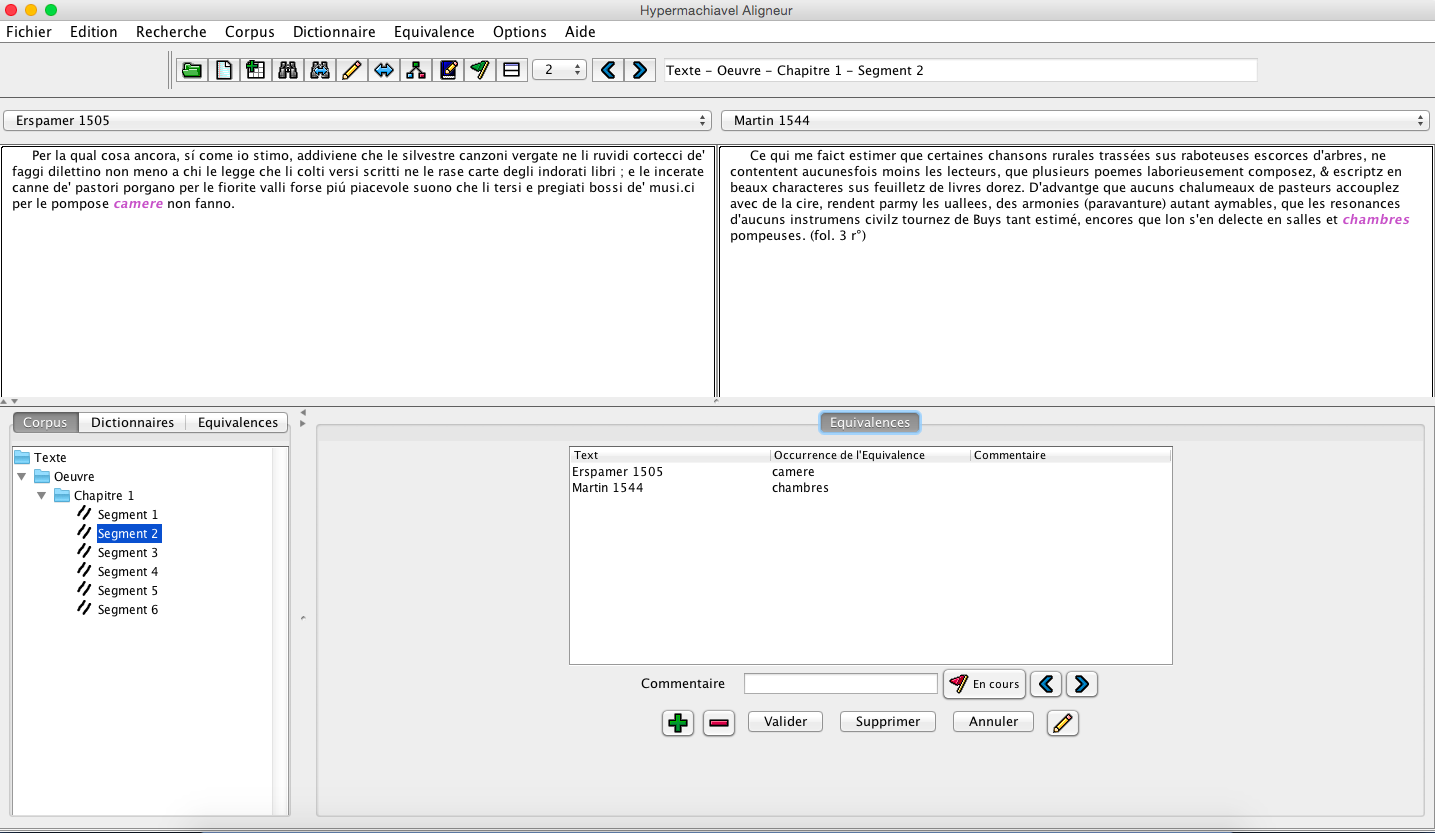
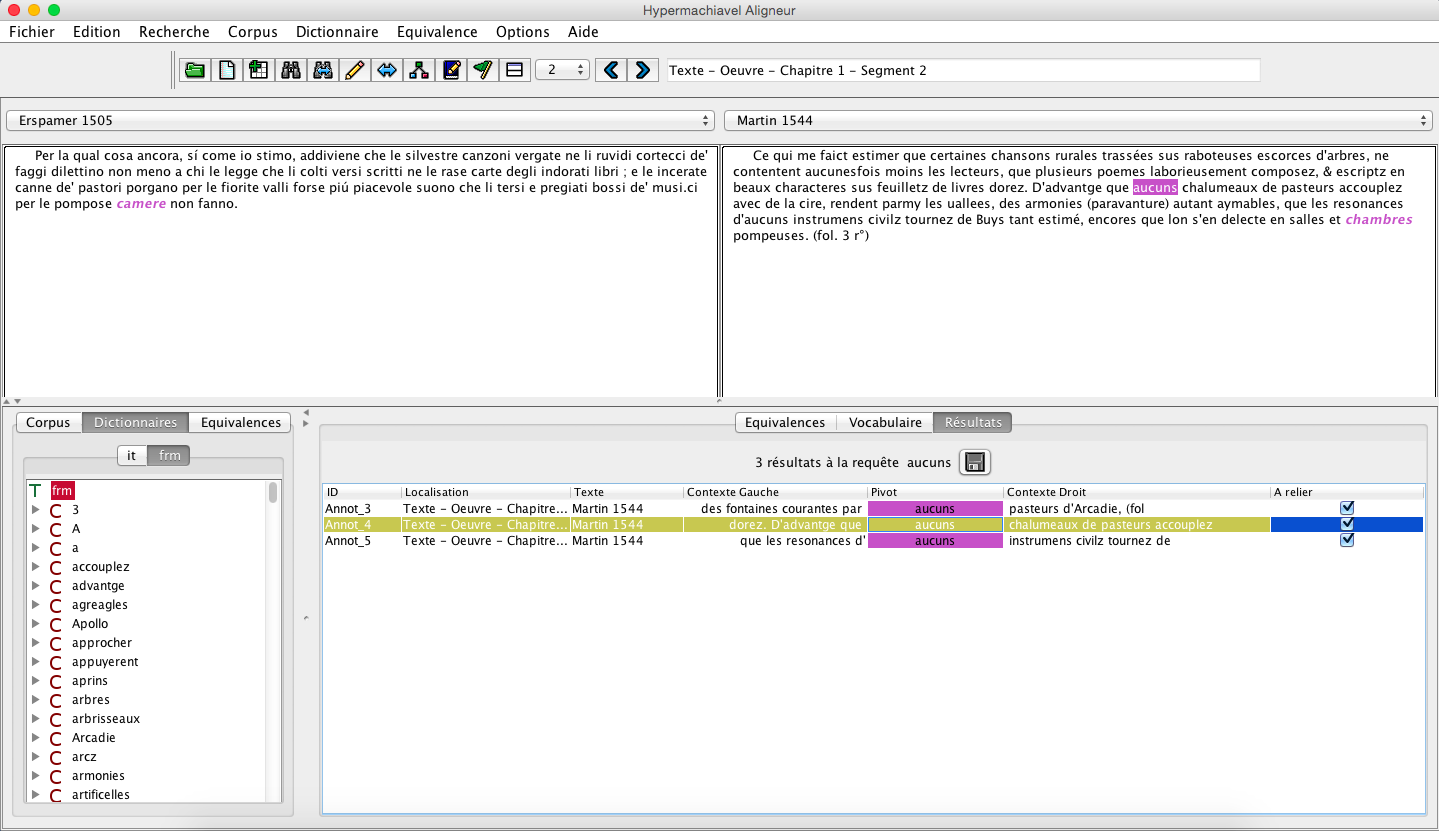
3) Importation dans Hypermachiavel¶
Il faut ouvrir l'outil (voir la documentation officielle à cette page) puis suivre les étapes de la création d'un projet corpus.
La tokenisation et lemmatisation est un processus plus ou moins long et ne sera effectué qu'à cette étape de création. Par la suite il faudra seulement ouvrir le projet constitué (voir la documentation officielle à cette page).
OXGarage_convertODT-2-TEI.png (145,59 ko)
{kind=link}
tei2teiHM.py
 (15,09 ko)
(15,09 ko)
CorpusSANAZIFR_Uetani_2017.xml
(751,7 ko)
CorpusSANAZIFR_Uetani_2017.odt (302,79 ko)
HM_HyperArcadia_AnnotateTranslationEquivalences.png (121,23 ko)
{kind=link}
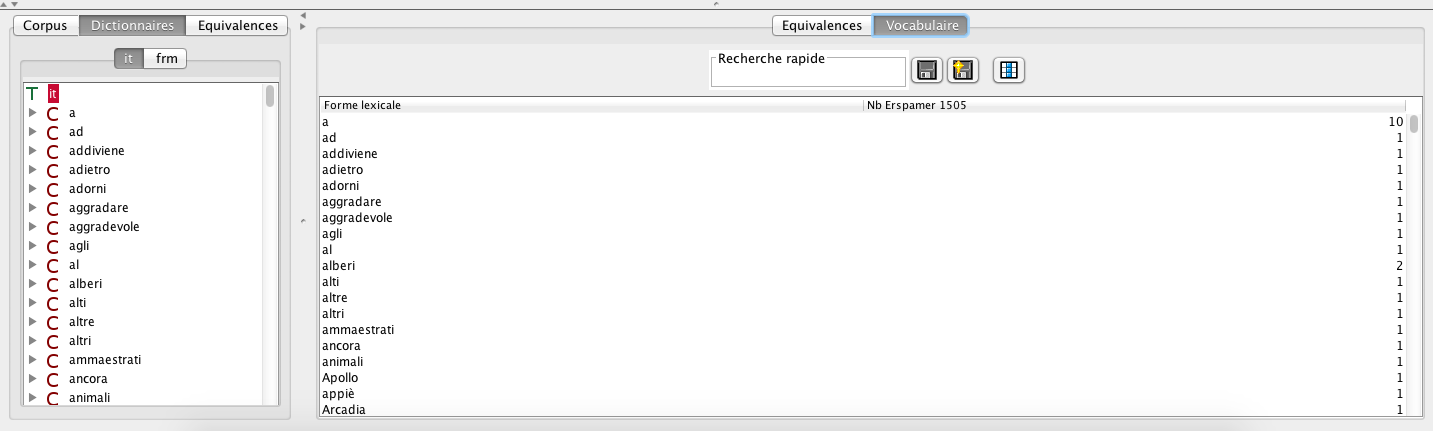
HM_HyperArcadia_ItalianLexicon_list.png (65,92 ko)
{kind=link}
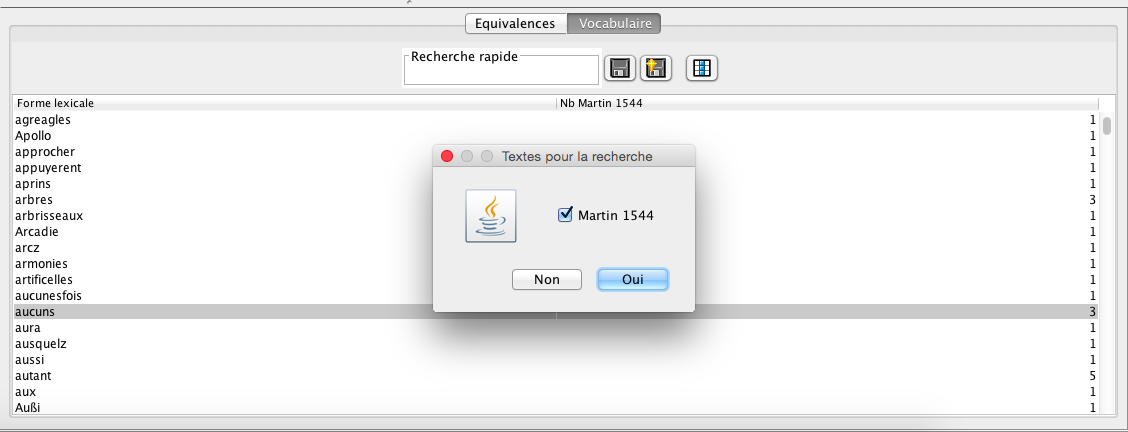
HM_HyperArcadia_ItalianLexicon_selection.png (68,07 ko)
{kind=link}
HM_HyperArcadia_KWIC_example.png (139,98 ko)
{kind=link}
Column.gif (953 octet)
{kind=link}
CorpusSANAZIFR_Uetani_2017_modifTable.xml
(751,17 ko)
HyperPrince.xml
(150,82 ko)