« Précédent -
Version 3/28
(diff) -
Suivant » -
Version actuelle
Severine Gedzelman, 26/09/2017 15:07
Transformation vers un corpus parallèle (alignement HM)¶
Le document fourni par Uetani est un fichier word, organisé avec des tableaux à 3 colonnes :- col 1 : nom du segment philologique (et notes diverses, dont certains acronymes sont à élucider pour moi)
- col 2 : version italienne
- col 3 : version française correspondante
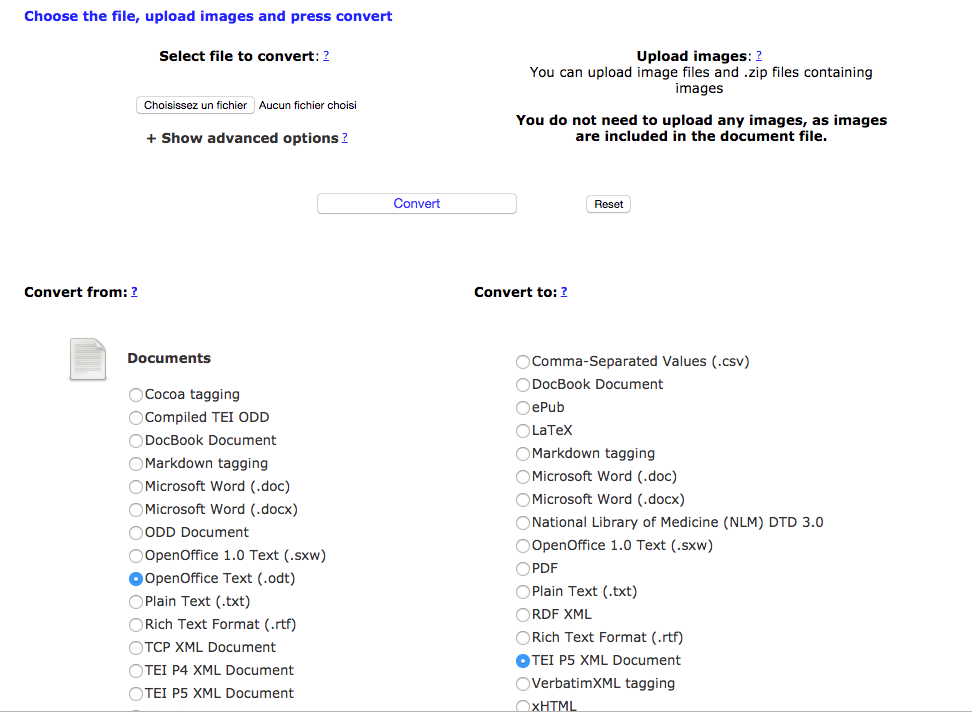
- le premier est fourni par le service OXGarage (transformateur en ligne pour la communauté TEI principalement)
- le deuxième a été écrit en python par moi-même dont les détails sont après.
ODT vers XML-TEI¶
- Le document de départ : CorpusSANAZIFR_Uetani_2017.odt
- Le document de sortie : CorpusSANAZIFR_Uetani_2017.xml
Les choix ont été les suivants :
XML-TEI vers XML-TEI-HM¶
Le script tei2teiHM.py permet de- récupérer uniquement le texte :
- sans les notes (de bas de page)
- sans les indications graphiques (qui sont dans des balises <hi> avec attributs : italic, bold, ...)
- et de préparer la structure et les noms des divisions, segments dans celles-ci (voir le chapitre sur la structure philologique, et les opérations de nettoyage) comme "Prosa_X_3-4" (A NOTER CE QUE CELA SIGNIFIE !!)
$ python tei2teiHM.py CorpusSANAZIFR_Uetani_2017.xml ~/Documents/Travail_ENS/Projets/Exterieurs/CESR_Uetani/Transformations
OXGarage_convertODT-2-TEI.png (145,59 ko)
{kind=link}
tei2teiHM.py
 (15,09 ko)
(15,09 ko)
CorpusSANAZIFR_Uetani_2017.xml
(751,7 ko)
CorpusSANAZIFR_Uetani_2017.odt (302,79 ko)
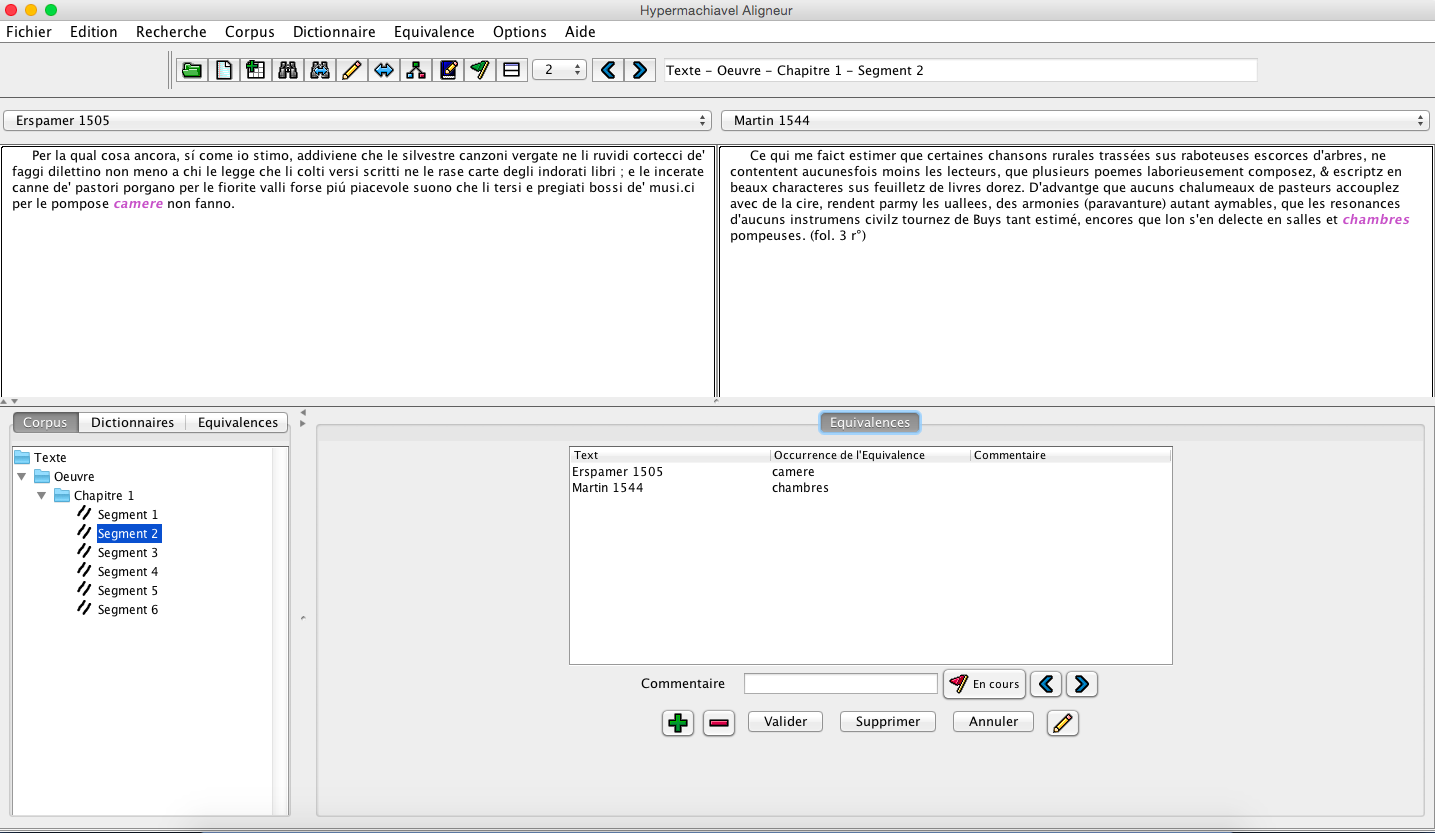
HM_HyperArcadia_AnnotateTranslationEquivalences.png (121,23 ko)
{kind=link}
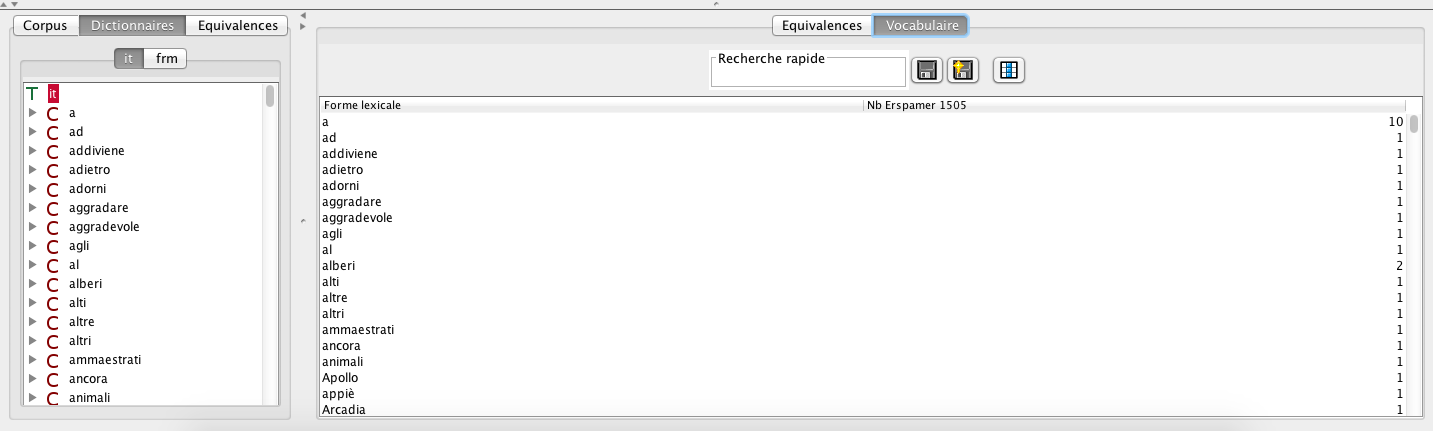
HM_HyperArcadia_ItalianLexicon_list.png (65,92 ko)
{kind=link}
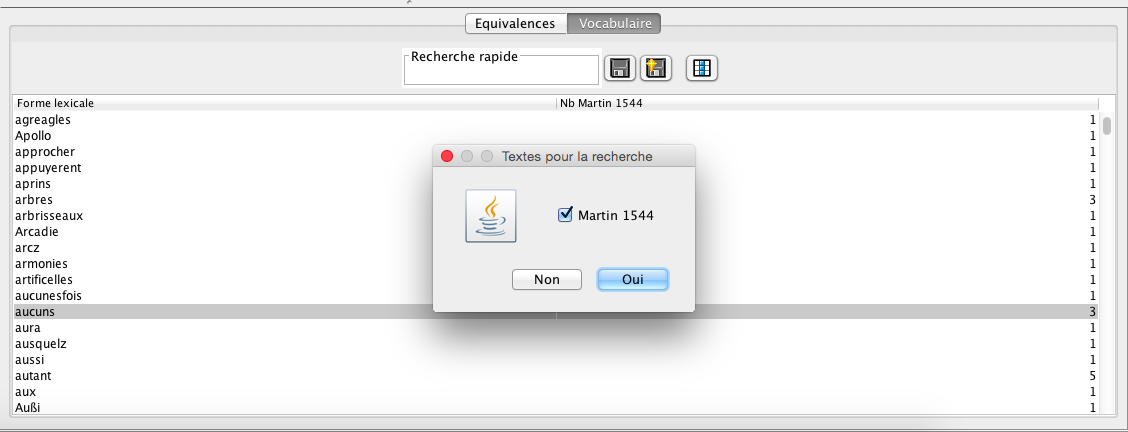
HM_HyperArcadia_ItalianLexicon_selection.png (68,07 ko)
{kind=link}
HM_HyperArcadia_KWIC_example.png (139,98 ko)
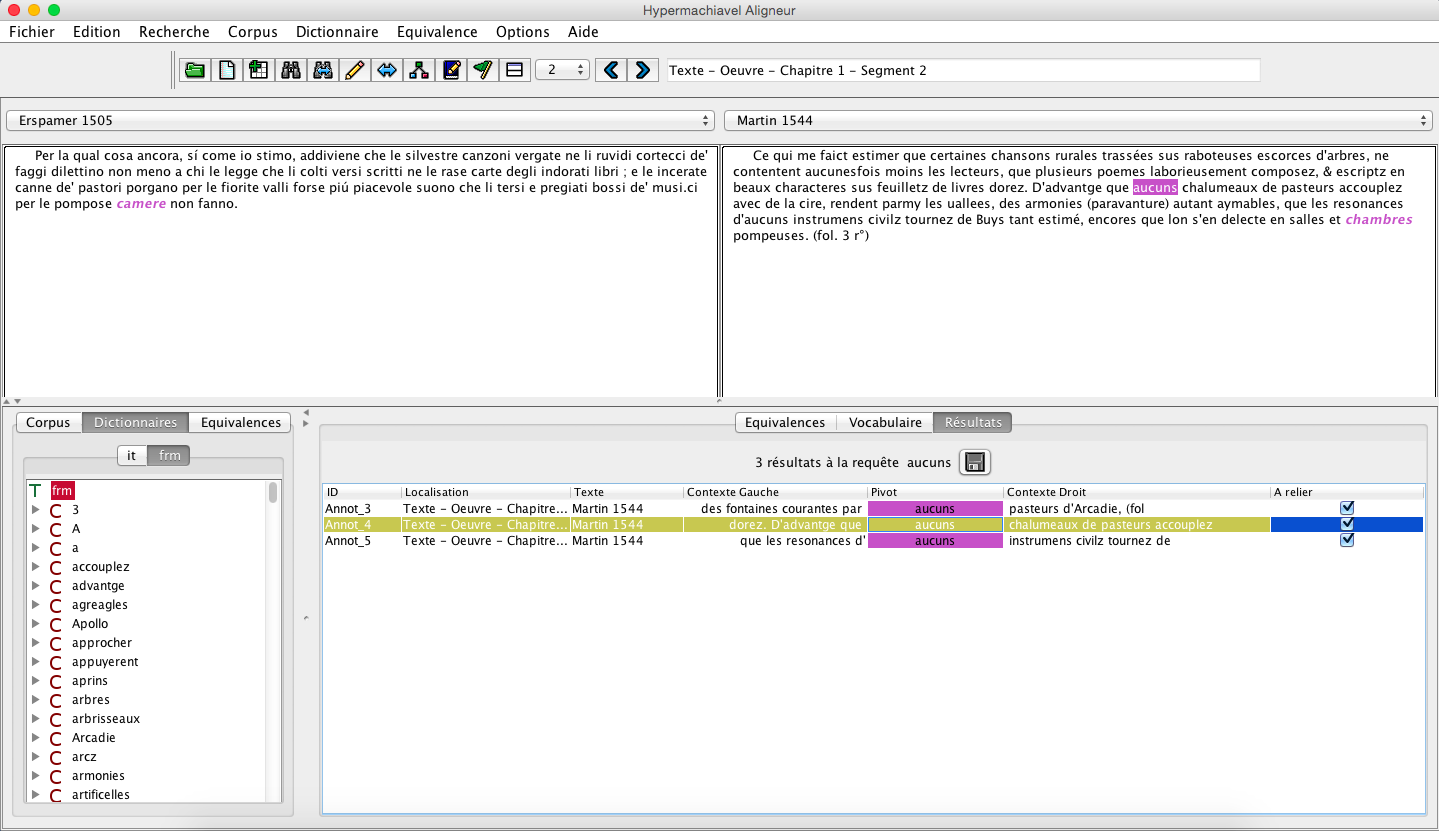{kind=link}
Column.gif (953 octet)
{kind=link}
CorpusSANAZIFR_Uetani_2017_modifTable.xml
(751,17 ko)
HyperPrince.xml
(150,82 ko)